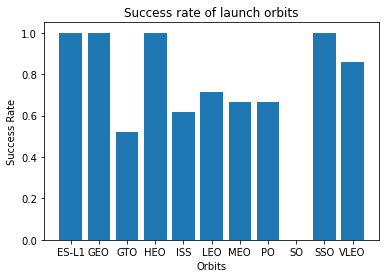
Project 1: Winning Space Race
Final project of IBM Data Science Course
Goal
To develop an accurate predictive model for determining space race winners using machine learning techniques.
Summary
A data science project focused on predicting space race winners based on historical data. It involves data collection, data preprocessing, feature engineering, model training, and evaluation.
Key features
- Dataset collection from various sources
- Exploratory data analysis and visualization
- Feature engineering and selection
- Implementation of machine learning algorithms for prediction
- Model evaluation and performance analysis
%20vs%20Launch%20Site.png)
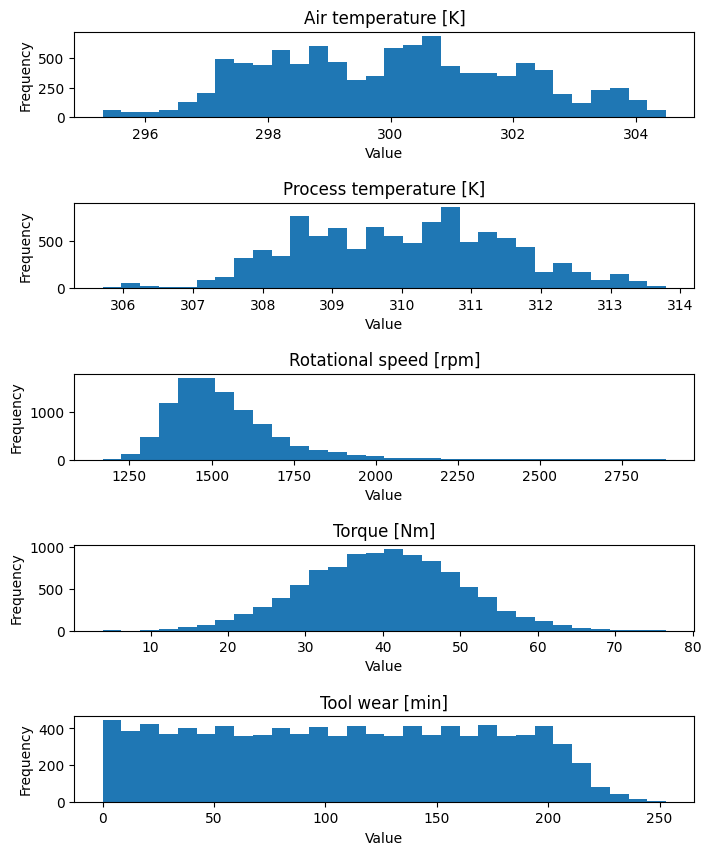
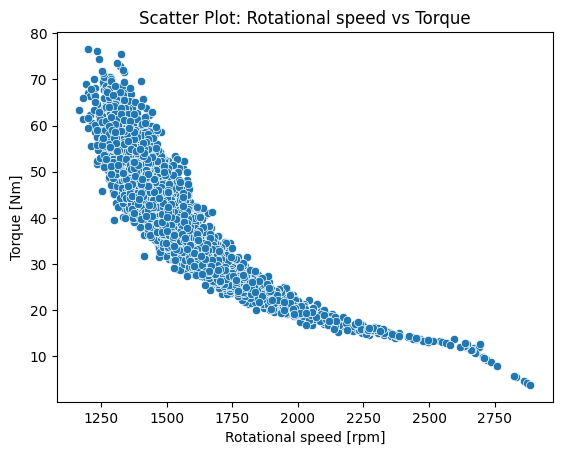
Project 2: Predictive Maintenance of Machines
Goal
The goal of this project is to develop an accurate predictive model for determining machine failure in a process using machine learning techniques.
Summary
This data science project revolves around the predictive maintenance of machines using a synthetical dataset. The project utilizes machine learning techniques, specifically logistic regression and random forest models, to develop accurate predictions for machine failure. The performance and effectiveness of these models are assessed thorough evaluation and analysis.
Key Features
- Exploratory data analysis and visualization
- Feature engineering and selection
- Implementation of machine learning algorithms for prediction of Machine failures
- Model evaluation and performance analysis
Project 3: Client Segmentation (Portuguese)
Goal
The primary objective of this project is to gain a comprehensive understanding of customers through effective client segmentation, enabling the provision of valuable insights for informed marketing strategies and optimized sales performance.
Summary
Two segmentation methods are used: RFM analysis and K-Means clustering. By employing these methods, the project aims to gain insights into customer behavior and preferences for effective marketing strategies.
Key Features
- Data Collection: Gathering raw data from the Google Merchandising Store to use as the primary dataset for customer segmentation.
- SQL Query: Constructing a SQL query in SQL Server Management Studio to extract relevant customer data, including converting users, sessions, transaction count, revenue, average revenue per transaction, and last transaction date.
- RFV Analysis: Implementing the RFV (Recency, Frequency, and Monetary Value) method for customer segmentation. Calculating recency, frequency, and monetary value metrics for each customer to identify distinct segments based on their purchasing behavior.
- K-Means Clustering: Utilizing the K-Means clustering algorithm, an unsupervised machine learning technique, to group customers into clusters based on similarities in RFV metrics. This allows for a more detailed understanding of customer segments.
- Comparison and Evaluation: Comparing the results of RFV segmentation and K-Means clustering to assess the effectiveness of each method in identifying customer segments. Evaluating the differences between the two approaches and their implications for marketing and communication strategies.
- Insights and Recommendations: Drawing meaningful insights from the customer segmentation analysis and using these insights to inform marketing strategies. Recommending tailored approaches for engaging with different customer segments based on their RFV profiles and clustering results.
- Documentation and Sharing: Providing comprehensive documentation of the project, including the SQL query, analysis techniques, and results. Sharing the project on GitHub to facilitate collaboration and knowledge sharing within the data science community.

